译者: bzhaoopenstack
作者: Krunal Bauskar
原文链接: https://mysqlonarm.github.io/NUMA-Smart-Global-Counter/
通过之前在X86, ARM虚机上的调研,与遇到的跨NUMA问题,结合自身在运行benchmark测试中的经验,让应用程序在针对特定的全局数据结构中更好的应用底层硬件,达到极致性能体验。下面来用数据说话。
在多线程系统中管理全局计数器一直是一项挑战。 它们是限制软件可扩展性的一大难题。NUMA 的引入只是增加了复杂性。 幸运的是,在硬件平台提供的支持下发现了多种选择,以帮助解决 / 缓解其中的一些问题。 在本博客中,我们将讨论如何使全局计数器感知NUMA,做到智能选择NUMA,并且看看每种方法对性能有什么影响。
注意: 很多这方面的工作都是受 MySQL 代码库的启发,是由于MySQL 代码库不断发展中会尝试解决这个问题。
全局计数器
大部分软件(例如: 数据库、web-server等等)都需要维持全局计数器。 由于是全局的,这些计数器只有一个副本,有多个工作线程试图更新它。 当然,这复杂的更新需要进行精细的协调,单从这一点,在性能上它就成为可伸缩性的热点分析对象。
另一种方式是松散地维护这些计数器(不加任何协调工作),但这意味着它们将表示一个近似的数字(特别是在竞争激烈的系统上)。这样不会对性能有过多影响,有一定的益处。
让我们看看当前生态系统提供了哪些方法来帮助解决这个问题。
配置说明
为了评估不同的方法,我们将考虑一个通用的设置。In order to evaluate different approaches we will consider a common setup.
- 试想一些counter-block,它们位于全局级别,因此所有线程都会时不时地更新它们
- 试想一些data-block(实际工作负载发生的地方) ,data-block的一部分操作会更新本地全局计数器。 每个数据块都有自己的本地计数器。 只要访问data-block,就会更新这些本地计数器。 这两个data-block是交错的。 请参阅以下的分布图
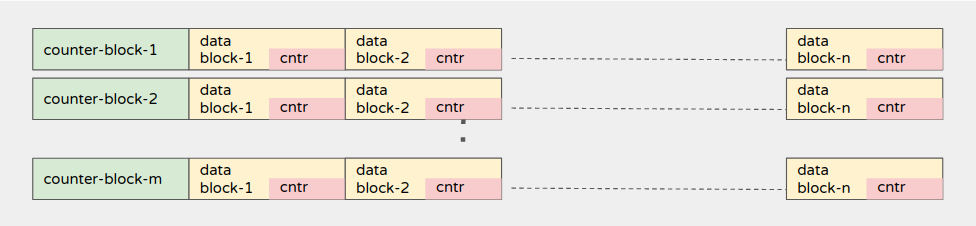
- 让我们通过一些简单的数值例子来理解这个结构。
- 假设我们有100个全局counter-block,每个data-block有10个counter。
- 假设我们有1000个全局data-block,它们与counter-block互相交织在一起。
- 这意味着,1-counter-block 计数器块之后是10个数据块,这样组合重复100次。
- 这样可以确保在 NUMA 节点上分布完整的内存块,并且在访问计数器和data-block时可以看到对NUMA 产生的影响。
- Workload (one-round):
- 将访问 n 个data-block(至少足以使 L2缓存失效)。
- 作为data-block访问的一部分,还更新与data-block相关联的本地计数器。 data-block是使用 rand ()函数随机选择的,以确保扩散分布。
- 接下来是从counter-block访问和更新全局计数器。 随机选择counter-block,并从中随机选择一个计数器(inc 操作)。 重复 M次。
- Workload 循环 K 次(rounds).
- 每个线程执行上述Workload循环(K 次) ,从1-256 / 2048开始使用不同的可伸缩性进行基准测试。
注意: 计数器只是简单的uint64_t 值(目前只使用 inc 操作)。
如果您有兴趣了解更多关于这方面的信息,您可以随时查看这里的详细代码。
使用的硬件描述
- x86-vm: 24 vCPU (12 cores with HT), 48 GB memory, 2 NUMA nodes, Intel(R) Xeon(R) Gold 6266C CPU @ 3.00GHz (Ubuntu-18.04)
- arm-vm: 24 vCPU (24 cores), 48 GB memory, 2 NUMA nodes, Kunpeng 920 2.60 GHz (Ubuntu-18.04)
用于1-2048伸缩性测试的机器
- arm-bms: 128 physical cores, 1 TB of memory, 4 NUMA nodes, Kunpeng 920 2.60 GHz (CentOS-7.8)
我们的意图不是比较 x86和 ARM,而是比较 NUMA 对全局计数器的影响。
测试方案
作为实验的一部分,我们评估了从基础到高级的多种方法。
- pthread-mutex based: 保护计数器操作的简单 pthread mutexes
- std::mutex: C++11 支持的 std::mutexes,和pthread mutexes很像,但是更容易使用。
- std::atomic: C++11 原子变量。
- fuzzy-counter (来自mysql): 有 n 个 cacheline 对齐的插槽。 随机选择要更新的一个插槽。 若要计算计数器的总值,需要从所有槽中添加值。 没有用于保护槽操作的互斥对象 / 原子对象。 这意味着数值是近似的,但是当需要想之前计算总是时效果最好。 我们将在结果部分看到一个方差系数。[ref: ib_counter_t. N 通常是核心的数量]
- shard-atomic-counter (来自mysql): 计数器被分割成 N个分片(如上面的 slot)。 每个处理流程都需要知道更新哪个分片。 为了高效的访问,分片都做了cacheline对齐。 [ ref: Counter: : Shard ]
- shard-atomic-counter (thread-id based): 计数器被分割成 N 个分片(如上面的槽)。 根据执行线程的线程 id 选择要更新的分片。 为了高效的访问,分片都做了cacheline对齐。[这里 N是活动核心的数量]
shard-atomic-counter (cpu-id based): 计数器被分割成 N个分片。 根据执行核心的 core-id 选择要更新的分片。 为了高效的访问,分片都做了cacheline对齐。[这里N是活动核心的数量。使用sched_getcpu获得cpu-id]
shard-atomic-counter (numa-id based): 计数器被分成 N 个分片。 根据执行核心的 numa-node-id 选择要更新的碎片。 为了高效的访问,分片都做了cacheline对齐。 [这里 N 是活动节点数。 N比较小,在2 / 4 / 8范围内,不是32 / 64 / 128 /等]
值得一提的是Mysql 内部还有另一个计数器结构 ut_lock_free_cnt_t()。 它尝试为各自 NUMA 上的每个计数器(值)分配内存,但是在每个numa_alloc_onnode种,即使是8个字节的小块也会按照系统页面大小的分配( Linux 4KB)。 这是大大的空间浪费。 我尝试过这种方法,但由于超负荷的巨大内存,最终没能成功分配内存。
让我们找出哪种方法在 NUMA 环境中最有效。
Benchmarking
使用上面解释的结构和workflow进行基准测试。 每次运行分配好内存后,然后为每个可伸缩性测试运行 K 轮Workflow。 下面的Timing 包括处理数据和计数器的时间,但大部分时间来自计数器争用(通过压制data-block处理已确认)。
- x86-vm [x轴: threads(1-256), y轴: time秒. 越低越好]
数据集: 100 个global counter-block, 每个block中10个counter, 1m data-blocks (每个block一个本地counter), 循环10K次
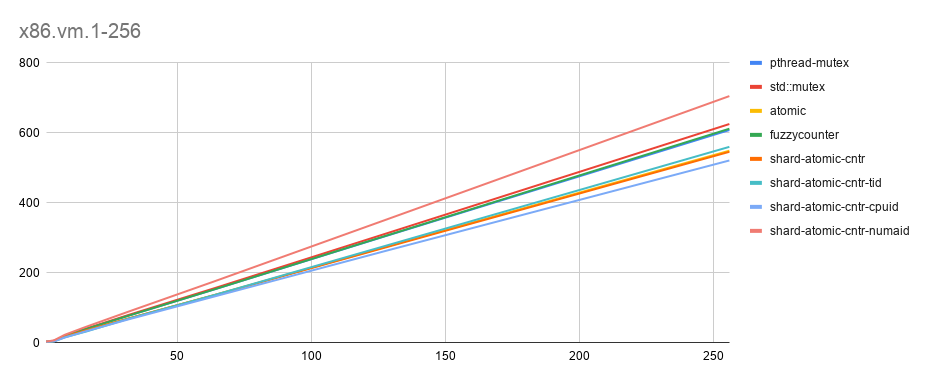
点评
- 正如预期的那样,带有 cpu-id 的 shard-atomic-counter 性能最好。
- 值得注意的是,简单的原子操作也是最佳的,并且节省了大量的空间。(没有cacheline对齐)。可能是 VM 影响的
- 另一个无法解释的行为: fuzzy counter被认为是最快的,但是测试中它不是最快的(我运行了3次同样的benchmark测试证实了这个现象。 在 ARM 上,它表现如预期的那样,因此不像是在基准测试代码出错导致的,需要再分析一下)。
直线非常接近 / 重叠,因此为了确切的表述,共享一下具体数据。
| threads | p-mutex | std-mutex | atomic | fuzzy | shard-rand | shard-tid | shard-cpuid | shard-numaid |
|---|---|---|---|---|---|---|---|---|
| 128 | 305.89 | 312.78 | 275.21 | 306.62 | 273.52 | 278.14 | 263.5 | 352.45 |
| 256 | 608.21 | 625.37 | 549.15 | 611.97 | 546.04 | 560.18 | 521.25 | 705.17 |
- arm-vm [x轴: threads(1-256), y轴: time秒. 越低越好]
数据集: 100 个global counter-block, 每个block中10个counter, 1m data-blocks (每个block一个本地counter), 循环10K次
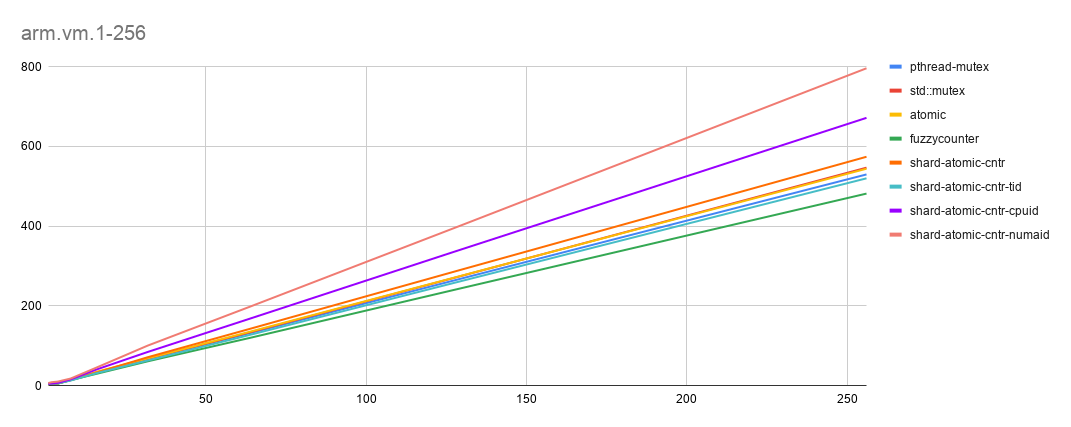
点评
- 同样,shard-atomic-counter (这次使用 thread-id)的得分高于其他方法。 (原因之一可能是在ARM上消耗巨大的sched_getcpu)。 [对于thread-id,线程开始时,在线程本地存储中缓存该线程的唯一标识符]
- FuzzyCounter正在帮助建立基线(假设没有争用的情况下)。
- 老旧的 pthread-mutex 似乎也得到了优化
- 令人感兴趣的是,随着可伸缩性的增加,ARM 似乎显示出较低的争用(可能是由于 NUMA 的互连性更好)。
直线线条非常接近,在某些情况下也会重叠,因此为了更好的表述,数据如下。
| threads | p-mutex | std-mutex | atomic | fuzzy | shard-rand | shard-tid | shard-cpuid | shard-numaid |
|---|---|---|---|---|---|---|---|---|
| 128 | 265.05 | 271.53 | 272.06 | 241.26 | 287.1 | 258.9 | 337.2 | 396.88 |
| 256 | 529.74 | 546.74 | 544.07 | 481.71 | 574.05 | 520 | 671.63 | 795.92 |
- arm-bms [x轴: threads(1-2048), y轴: time秒. 越低越好]
数据集: 100 个global counter-block, 每个block中10个counter, 1m data-blocks (每个block一个本地counter), 循环1K次
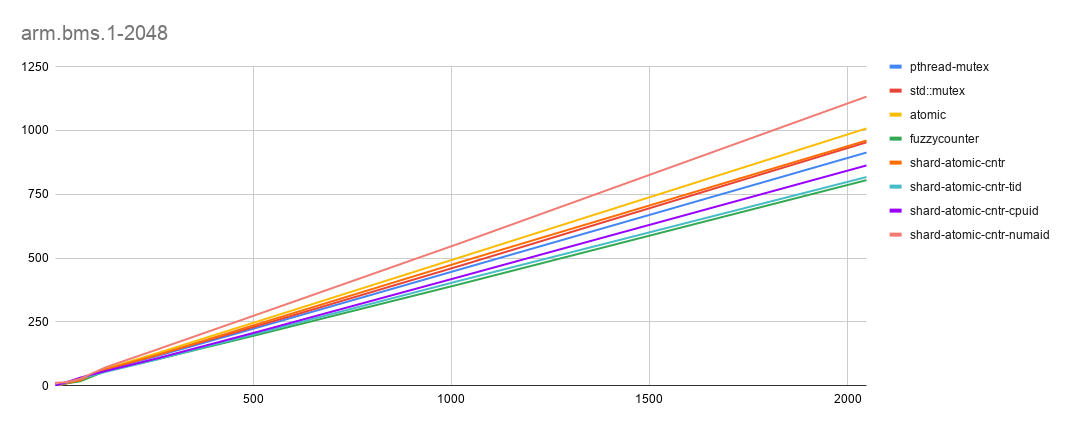
点评
- Fuzzy-Counter 帮助设置基线,但是这次我们看到 shard-atomic-counter (带有thread-id)几乎与 Fuzzy-Counter (无争用情况)相当。 似乎这就是预期的最佳数字。
直线非常接近,在某些情况下也会重叠,因此为了更好的表述,参看下列具体数据。 以防你没有注意到测试循环次数已经减少到了1K。 由于跨NUMA访问和增加的可伸缩性,保持循环10K次可能会造成更多的时间消耗,也会有更多的噪音。 (注意: 我们现在裸机有4个 NUMA节点)。
| threads | p-mutex | std-mutex | atomic | fuzzy | shard-rand | shard-tid | shard-cpuid | shard-numaid |
|---|---|---|---|---|---|---|---|---|
| 128 | 62.81 | 63.9 | 66.24 | 57.37 | 64.24 | 54.09 | 57.67 | 72.08 |
| 256 | 115.39 | 119.53 | 126.52 | 102.68 | 119.01 | 102.13 | 106.3 | 140.83 |
| 512 | 228.2 | 234.5 | 252 | 199.71 | 241.69 | 205.66 | 211.29 | 279.81 |
| 1024 | 456.53 | 470.55 | 503.73 | 398.61 | 484.82 | 412.43 | 427.52 | 559.21 |
| 2048 | 913.58 | 953.56 | 1007.94 | 805.35 | 960.53 | 817.45 | 862.94 | 1132.56 |
让我们看看fuzzy-counter的近似因子,区别不是很大。
| threads | global-counter (expected) | global-counter (actual) |
|---|---|---|
| 128 | 20480000 | 20479994 |
| 256 | 40960000 | 40959987 |
| 512 | 81920000 | 81919969 |
| 1024 | 163840000 | 163839945 |
| 2048 | 327680000 | 327679875 |
总结
Benchmark测试证明了,对全局计数器使用 CPU/thread 亲和性的性能最好。 当然,x86和 ARM 有不同的优化点,因此可以相应地调整 MySQL。 Fuzzy counter替换为atomic (或shard-atomic),可以更好的节省空间和提高精度(在 x86平台上)。
如果你有问题 / 疑问,请联系我。
Managing global counters in a multi-threaded system has always been challenging. They pose serious scalability challenges. Introduction of NUMA just increased the complexity. Fortunately multiple options have been discovered with hardware lending support to help solve/ease some of these issues. In this blog we will go over how we can make Global Counter NUMA SMART and also see what performance impact each of this approach has.
Note: a lot of this work is inspired from MySQL codebase that is continuously trying to evolve to solve this issue.
Global Counters
Most of the software (for example: database, web-server, etc…) needs to maintain some global counters. Being global, there is one copy of these counters and multiple worker threads try to update it. Of-course this invites a need of coordination while updating these copies and in turn it becomes scalability hotspots.
Alternative is to loosely maintain these counters (w/o any coordination) but that means they will represent an approximate number (especially on a heavily contended system). But they have their own benefits.
Let’s see what all approaches the current ecosystem provides to help solve this problem.
Setup
In order to evaluate different approaches we will consider a common setup.
- Let’s consider some global counters that are at global level so all threads update them once in a while.
- Let’s consider some data-blocks (where the real workload happens) and as part of this action global counters are updated. Each data-block has its own local counter(s). These local counters are updated whenever data-block is accessed. Both of these blocks are interleaved. Check the arrangement below.
- Let’s try to understand this structure with some simple numeric examples.
- Say we have 100 global counter-blocks and each data-block has 10 counters.
- Say we have 1000 global data-blocks that are equally interleaved with each counter block.
- That means, 1-counter-block is followed by 10-data-blocks and this combination repeats 100 times.
- This ensures complete memory blocks are distributed across NUMA nodes and we get to see the effect of NUMA while accessing the counters and data-blocks too.
- Workload (one-round):
- Flow will access N data-blocks (at-least enough to invalidate L2 cache).
- As part of the data-block access, local counter(s) associated with the data-block are also updated. Data blocks are randomly selected using rand() function to ensure spread-across distribution.
- This is followed with the access and update of global counters from the counter-block. Random counter-block is selected and a random counter from the selected counter block is updated (inc operation). This operation is repeated M times.
- Workload loop is repeated K times (rounds).
- Each thread executes the said workload loop (K times). Benchmarking is done with different scalability starting from 1-256/2048.
Note: Counter is simply uint64_t value (currently using inc operation only).
If you are interested in understanding more about this you can always check out the detailed code here.
Hardware used
For scaling from 1-256
- x86-vm: 24 vCPU (12 cores with HT), 48 GB memory, 2 NUMA nodes, Intel(R) Xeon(R) Gold 6266C CPU @ 3.00GHz (Ubuntu-18.04)
- arm-vm: 24 vCPU (24 cores), 48 GB memory, 2 NUMA nodes, Kunpeng 920 2.60 GHz (Ubuntu-18.04)
For scaling from 1-2048
- arm-bms: 128 physical cores, 1 TB of memory, 4 NUMA nodes, Kunpeng 920 2.60 GHz (CentOS-7.8)
Idea is not to compare x86 vs ARM but the idea is to compare the effect of NUMA on the global counter.
Approches
As part of the experiment we evaluated different approaches right from basic to advanced.
- pthread-mutex based: Simple pthread mutexes that protects operation on counter
- std::mutex: C++11 enabled std::mutexes just like pthread mutexes but more easier to use with inherent C++11 support.
- std::atomic: C++11 atomic variable.
- fuzzy-counter (from mysql): There are N cacheline aligned slots. Flow randomly selects one of the slots to update. To find out the total value of the counter, add value from all the slots. There are no mutexes/atomic that protect the slot operations. This means value is approximate but works best when the flow needs likely count. We will see a variance factor below in result section. [ref: ib_counter_t. N is typically = number of cores].
- shard-atomic-counter (from mysql): Counter is split into N shards (like slot above). Each flow tells which shard to update. Shards are cache lines aligned for better access. [ref: Counter::Shard]
- shard-atomic-counter (thread-id based): Counter is split into N shards (like slot above). Shard to update is selected based on thread-id of executing thread. Shards are cache lines aligned for better access. [here N is number-of-active-cores]
- shard-atomic-counter (cpu-id based): Counter is split into N shards. Shard to update is selected based on core-id of executing core. Shards are cache lines aligned for better access. [here N is number-of-active-cores. cpu-id obtained using sched_getcpu].
- shard-atomic-counter (numa-id based): Counter is split into N shards. Shard to update is selected based on numa-node-id of the executing core. Shards are cache lines aligned for better access. [here N is number-of-active-numa-nodes. N is small here in the range of 2/4/8 not like 32/64/128/etc…]
There is another counter structure inside MySQL that is worth mentioning ut_lock_free_cnt_t(). It tries to allocate memory for each counter (value) on respective NUMA but as per the numa_alloc_onnode even a smaller chunk of 8 bytes will cause allocation of system-page size (for Linux 4KB). That is too much space wastage. I tried this approach but eventually failed to allocate memory due to enormous memory over-head.
Idea is to find out which approach works best in the NUMA environment.
Benchmarking
Benchmarking is done using the structure and workload explained above. Each run allocates memory and then K rounds of workload loop per scalability. Timing below includes time to process data and counter but majority of it is coming from counter contention (confirmed by supressing data-block processing).
- x86-vm [x-axis: threads(1-256), y-axis: time in seconds. Lesser is best]
Data-set: 100 global counter blocks, 10 counters per block, 1m data-blocks (with a local counter per block), 10K rounds
Comments
- As expected, shard-atomic-counter with cpu-id performs best. (cpu-id = sched_getcpu).
- Suprisingly, simple atomic is optimal too with significant space saved. (No cacheline alignment). May be VM effect.
- Another unexplained behavior: fuzzy counter which is expected to be fastest is not showing up to be fastest (I re-confirmed this behavior with 3 different runs. On ARM, it performing as expected so less likely something going wrong in the benchmarking code. More analysis to be done).
Lines are pretty close/overlapping, so sharing the numeric numbers for higher-sclalability.
| threads | p-mutex | std-mutex | atomic | fuzzy | shard-rand | shard-tid | shard-cpuid | shard-numaid |
|---|---|---|---|---|---|---|---|---|
| 128 | 305.89 | 312.78 | 275.21 | 306.62 | 273.52 | 278.14 | 263.5 | 352.45 |
| 256 | 608.21 | 625.37 | 549.15 | 611.97 | 546.04 | 560.18 | 521.25 | 705.17 |
- arm-vm [x-axis: threads(1-256), y-axis: time in seconds. Lesser is best]
Data-set: 100 global counter blocks, 10 counters per block, 1m data-blocks (with a local counter per block), 10K rounds
Comments
- Again, shard-atomic-counter (this time with thread-id) scored better than other alternatives. (one of the reason could be sched_getcpu is costly on ARM). [For thread-id, flow cached thread unique identifier during creation, in thread-local storage].
- FuzzyCounter is helping establish baseline (given there is no-contention).
- Good old pthread-mutex seems to be optimized too.
- Intererstingly, ARM seems to be showing lower contention with increase scalability (may be due to better NUMA interconnect).
Lines are pretty close and in some cases overlapping too, so sharing the numeric numbers for higher-sclalability.
| threads | p-mutex | std-mutex | atomic | fuzzy | shard-rand | shard-tid | shard-cpuid | shard-numaid |
|---|---|---|---|---|---|---|---|---|
| 128 | 265.05 | 271.53 | 272.06 | 241.26 | 287.1 | 258.9 | 337.2 | 396.88 |
| 256 | 529.74 | 546.74 | 544.07 | 481.71 | 574.05 | 520 | 671.63 | 795.92 |
- arm-bms [x-axis: threads(1-2048), y-axis: time in seconds. Lesser is best]
Data-set: 100 global counter blocks, 10 counters per block, 1m data-blocks (with a local counter per block), 1K rounds
Comments
- Fuzzy-Counter help set the baseline but this time we see shard-atomic-counter (with thread-id) is almost on-par with Fuzzy-Counter (non-contention use-case). That is like optimal number to expect.
Lines are pretty close and in some cases overlapping too, so sharing the numeric numbers for higher-sclalability. Just incase you have not noticed the rounds has been reduced by 1K. Keeping it 10K increases timing like anything due to cross-numa access and increased scalability. (note: we are now on operating machine with 4 numa nodes).
| threads | p-mutex | std-mutex | atomic | fuzzy | shard-rand | shard-tid | shard-cpuid | shard-numaid |
|---|---|---|---|---|---|---|---|---|
| 128 | 62.81 | 63.9 | 66.24 | 57.37 | 64.24 | 54.09 | 57.67 | 72.08 |
| 256 | 115.39 | 119.53 | 126.52 | 102.68 | 119.01 | 102.13 | 106.3 | 140.83 |
| 512 | 228.2 | 234.5 | 252 | 199.71 | 241.69 | 205.66 | 211.29 | 279.81 |
| 1024 | 456.53 | 470.55 | 503.73 | 398.61 | 484.82 | 412.43 | 427.52 | 559.21 |
| 2048 | 913.58 | 953.56 | 1007.94 | 805.35 | 960.53 | 817.45 | 862.94 | 1132.56 |
Let’s see approximation factor for fuzzy-counter. Not that major difference.
| threads | global-counter (expected) | global-counter (actual) |
|---|---|---|
| 128 | 20480000 | 20479994 |
| 256 | 40960000 | 40959987 |
| 512 | 81920000 | 81919969 |
| 1024 | 163840000 | 163839945 |
| 2048 | 327680000 | 327679875 |
Conclusion
Benchmark study has proved that using CPU/thread affinity for global counters works best. Of-course x86 and ARM has different optimization point so MySQL could be tuned accordingly. Fuzzy counter could be better replaced with atomic (or shard-atomic) given space saved and improved accurancy (on x86).
If you have more questions/queries do let me know. Will try to answer them.