译者: bzhaoopenstack
作者: Krunal Bauskar
原文链接: https://mysqlonarm.github.io/Understanding-Memory-Barrier/
组内Mysql大牛Krunal利用Mysql EventMutex来让你彻底理解内存屏障问题,如何优化等。中文版实在是不好翻译,强烈建议阅读英文版增加理解。瓜已经备好了,还等啥?!
MySQL 有多种互斥实现,即封装在 pthread 上的、基于 futex 的、基于 Spin-Lock 的(EventMutex)。它们都有自己的优点和缺点,但由于长期以来 MySQL 一直默认使用 EventMutex,因为它被认为是 MySQL应用场景的最佳选择。
EventMutex 被转换为使用 C++原子操作(MySQL 增加了对C++ 11的支持)。鉴于 MySQL 现在也支持 ARM,正确地使用内存屏障也是保持 EventMutex 向前优化发展的关键。
在本文中,我们将使用 EventMutex 的一个示例,了解内存障碍,并查看缺少什么,可以优化什么等等。.
理解获取和释放内存顺序
ARM/PowerPC 平台使用弱内存模型,这意味着计算操作可以更自由地重新排序,因此同步地确保逻辑正确的屏障非常重要。最简单的方案是依赖使用循序一致性的默认方案(就像x86那样) ,但是这可能会大大影响其他架构的性能。
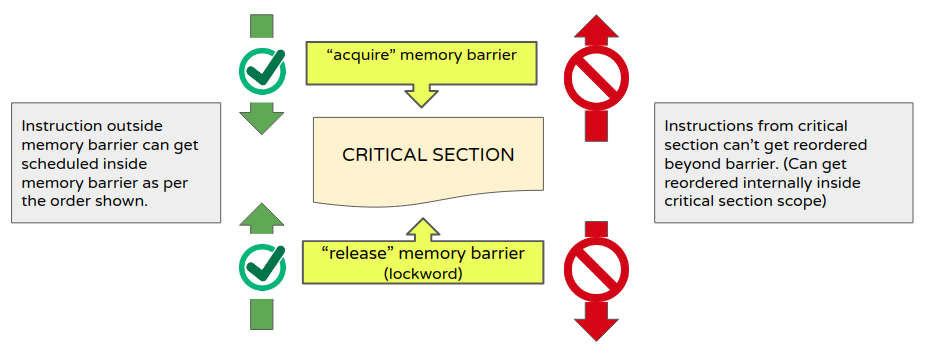
通常开发人员必须面对两个障碍(即 顺序) : 获取和释放。
- 获取内存顺序意味着在这个内存顺序/屏障之后的任何操作都不能调度/重新排序到该内存顺序/屏障之前(但是在获取该获取内存顺序之前的操作是可以调度/重新排序到它之后)
- 释放内存顺序意味着在这个内存顺序/屏障之前的任何操作都不能调度/重新排序到释放该内存顺序/屏障之后(但是在释放该获取内存顺序之后的操作是可以调度/重新排序到它之前)
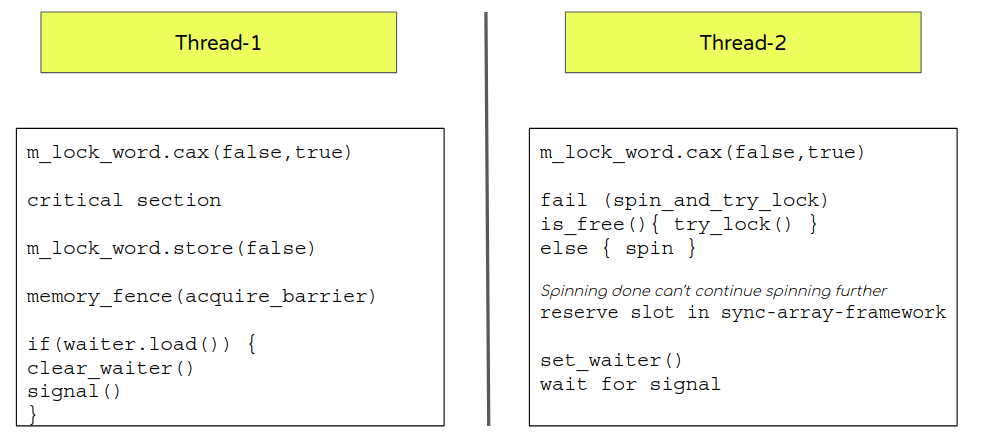
理解 EventMutex 结构
EventMutex 提供了一个普通的互斥类接口,用于帮助同步对临界区的访问。
- Enter (lock mutex)
- try_lock (如果获得锁,立即返回).
- 利用compare-and-exchange (CAX) 接口设置 m_lock_word 原子变量.
- 如果锁获取失败
- 进入一个自旋循环,多次尝试后暂停,检查锁是否再次可用。
- 如果在“ N”次尝试之后(由 innodb_sync_spin_loops 控制)锁仍然不可用,那么释放(释放 cpu 控制)并通过在 InnoDB 自制的同步数组(sync-array)中注册该线程,让其进入等待状态。另外,在保留插槽后设置一个等待标志(这样可以确保我们在 sync-array 中得到一个插槽)。等待标志是另一个用于协调信号机制的原子变量。
- try_lock (如果获得锁,立即返回).
- Exit (unlock mutex)
- 切换原子变量(m_lock_word)以表示离开临界区。
- 检查是否设置了等待标志。如果有设置,那么通过同步数组(sync-array)框架向等待线程发送信号来唤醒它们。
看起来非常简单直接。不是吗?
引入内存障碍会使这个过程变得复杂,因为忽略它们将意味着重新排序,这可能会导致代码中出现竞争。
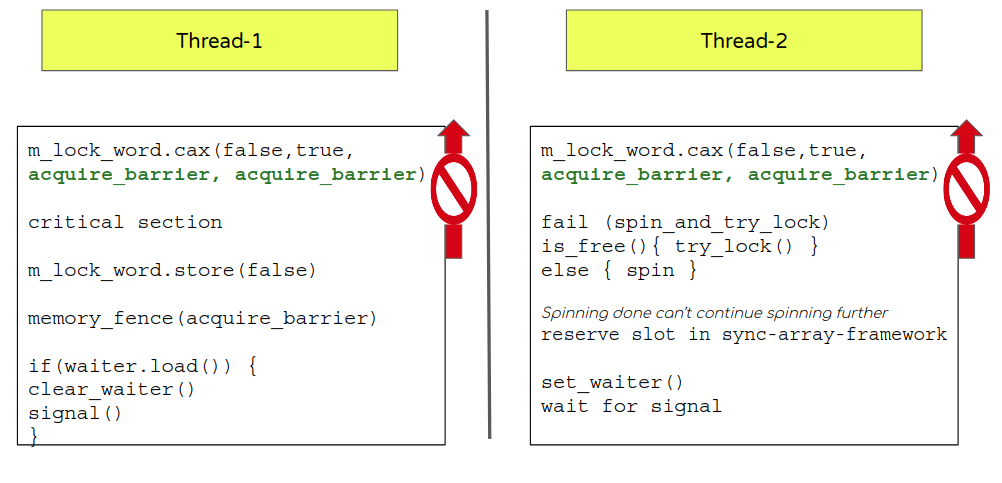
- 从上面的序列可以很清楚地看出,当锁定 m_lock_word (false-> true)时,它起始于临界区(如果 CAX 成功的话) ,因此在m_lock_word 被获取(设置为 true)之前,流程不应该执行来自临界区的任何语句。
- 回到我们的获取-释放屏障的部分,它建议 m_lock_word 应该能获取一个屏障一旦它成功了。 (而不是像它现在这样默认的保持顺序一致(seq_cst)).
- 但是,等等,有两个潜在的结果。失败怎么办?即使在失败的情况下,后续的执行,如自旋,睡眠等待和设置等待标识应该在CAX 评估后。这再次表明获得屏障失败的例子 (而不是像它现在这样默认的保持顺序一致(seq_cst)).
- 现在让我们看看 m_lock_word 释放屏障的例子。通常一个释放屏障过程发生在临界区结束要改变m_lock_word的时候。
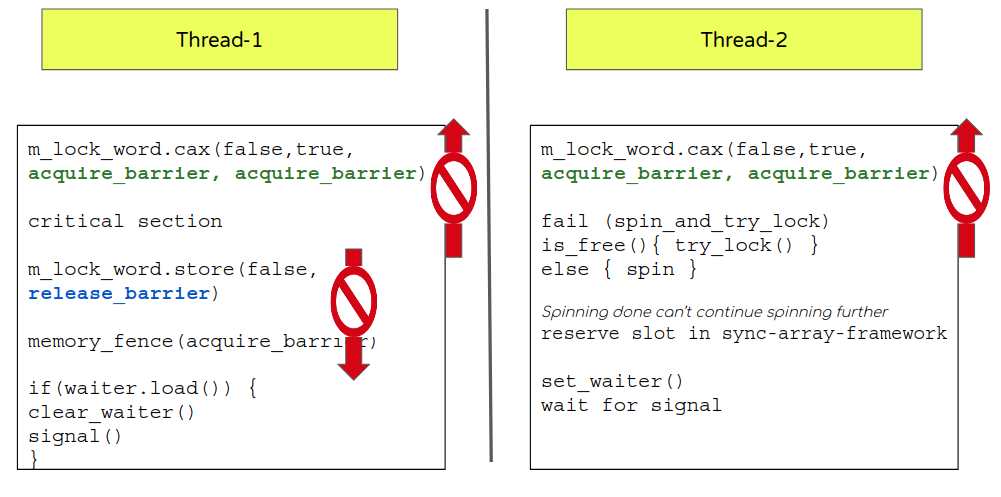
- 还有另外一个原子变量(等待标志)也需要一个合适的屏障
- 设置服务员标志的动作应该发生在只有当流程中已确保可以得到一个同步阵列(sync-array)插槽的时候。这自然而然就需要一个 释放屏障,在set_waiter以上的代码都不会被重新排序。注意: 这是不同的原子操作,所以这里不适用于协调m_lock_word 的获取和释放。
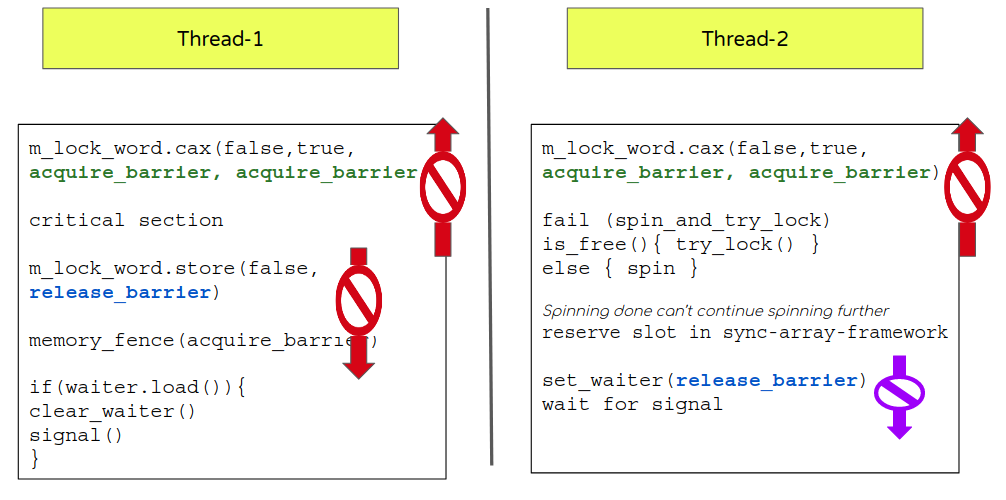
- 同样的信号相关的逻辑也应该在等待标志被清除之后再进行,所以它应该使用一个获取屏障,以确保在清除等待之前不会被重新调度。(而不是像现在这样释放)。
- 这也将帮助我们使用relaxed屏障(vs 获取)来改变waiter-load标志检查。(这里有一个潜在的问题,我们将在下面讨论)。
- 有了所有这些,我们也应该能够解决那些比较明显的内存屏障了。
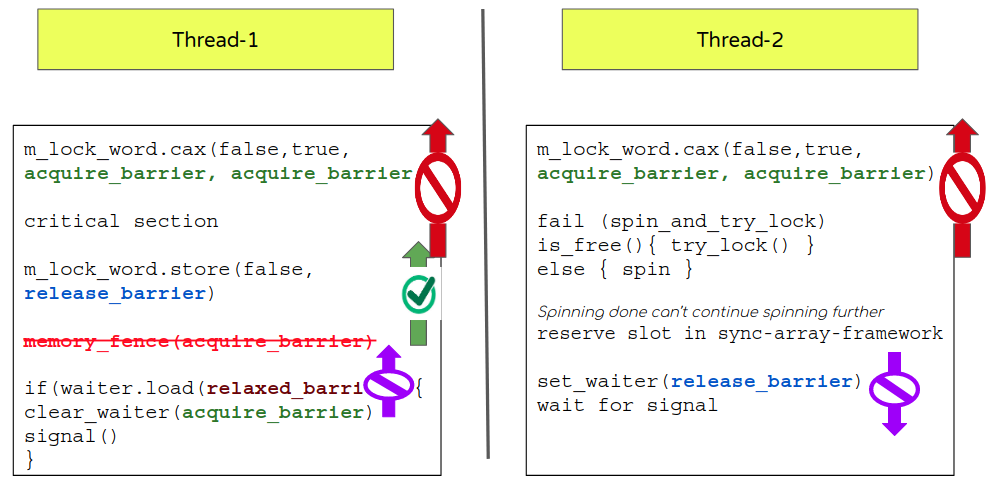
异常情况:
- 在release-barrier的
1 | lock_word |
在之后的 acquire-barrier
1 | waiter |
这是能够重新排序的。
- 这甚至是我对潜在风险的理解,我认为这就是为什么 MySQL 在这两个操作之间引入了一个内存屏障。如上所述blog, C++ 标准应该限制编译器这样做。
relaxed barrier
对于等待标识(同时检查其值时)有潜在的重新排序,可以将加载指令移动到 m_lock_word释放之前(注意:释放屏障 可以让后续的指示得到预先安排,就是排在它之前).
- If “waiter” is true then 调用信号循环来唤醒线程.
- If “waiter” is false then 信号循环将不会被该线程调用,而可能被其他线程调用。
- 如果只有2个线程,并且 thread-1通过在释放屏障之前重新排序得到 waiter = false,然后立即发布waiter被 thread-2设置为 true 并继续等待会怎么样。现在,thread-1 将永远不会向thread-2发出信号。
因此,使用一个relaxed 屏障是不可能的,所以让我们转换它使用一个获取屏障,应该避免移动后续语句超出上述情况,并作为澄清以上release-acquire需要遵循 C++ 标准。
所有这些都是为了节省额外的内存屏障。内存屏障的意图是协调同步非原子的操作,因为示例代码中有固有的原子(等待标志)使用适当的内存屏障可以帮助达到所需的效果。
所以有了这些注意事项,代码就会变成这样
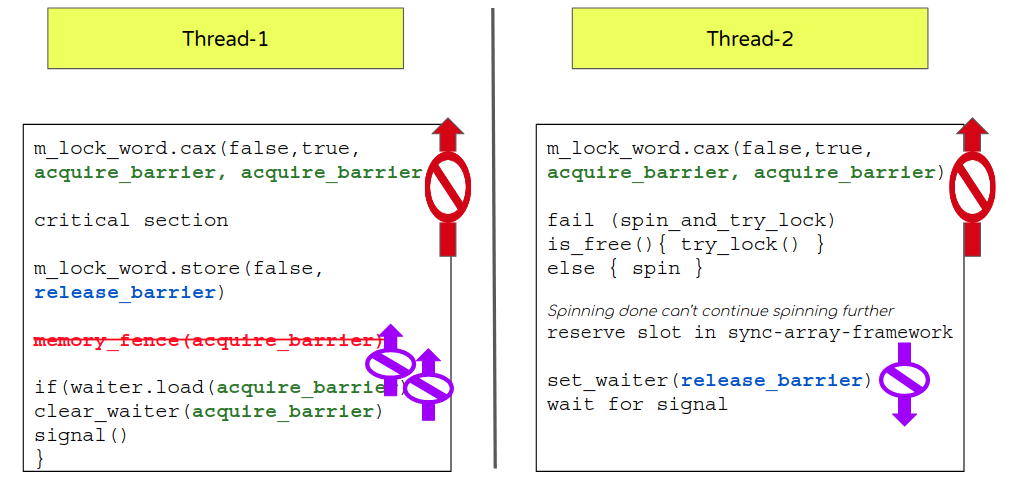
我们从这次代码改造中得到了什么?
我们实现了三个目标
- 修正了内存屏障的使用,这也有助于澄清代码/流程/开发人员的意图。(这是使用内存屏障所强调的重要事情之一。正确的使用将有助于使代码流程被理解和遵循)。
- 从严格的顺序排序移动到单向屏障而不失去正确性(获取和释放)
- 避免在非原子操作同步中使用内存屏障。
除非具有性能影响,否则没有理由进行改造,这次改造也不例外。改造后 ARM 的性能提高了4-15% ,x86_64的性能提高了4-6% 。
总结
原子操作是好的,但是内存障碍使它们面临挑战,并且确保正确使用内存屏障是在所有平台上获得最佳性能的关键。Barrier 的改造正在迎头赶上,但仍然在起步阶段(尽管在C+11中有所体现) ,因为大多数软件最近开始移植它。正确使用屏障也有助于描述开发者/代码的意图。
如果你有问题,请联系我。
MySQL has multiple mutex implementations viz. wrapper over pthread, futex based, Spin-Lock based (EventMutex). All of them have their own pros and cons but since long MySQL defaulted to EventMutex as it has been found to be optimal for MySQL use-cases.
EventMutex was switched to use C++ atomic (with MySQL adding support for C++11). Given that MySQL now also support ARM, ensuring a correct use of memory barrier is key to keep the EventMutex Optimal moving forward too.
In this article we will use an example of EventMutex and understand the memory barrier and also see what is missing, what could be optimized, etc…
Understanding acquire and release memory order
ARM/PowerPC follows weak memory model that means operations can be re-ordered more freely so ensuring the correct barrier with synchronization logic is important. Easiest alternative is to rely on a default one that uses sequential consistency (as done with x86) but it could affect performance big time on other architectures.
Often a programmer has to deal with 2 barriers (aka order): acquire and release.
- acquire memory order means any operation after this memory-order/barrier can’t be scheduled/re-ordered before it (but operations before it can be scheduled/re-ordered after it)
- release memory order means any operations before this memory-order/barrier can’t be scheduled/re-ordered after it (but operations after it can be scheduled/re-ordered before it).
Understanding EventMutex structure
EventMutex provides a normal mutex-like interface meant to help synchronize access to the critical sections.
- Enter (lock mutex)
- try_lock (try to get the lock if procured return immediately).
- Uses an atomic variable (m_lock_word) that is set using compare-and-exchange (CAX) interface.
- If fail to procure
- Enter a spin-loop that does multiple attempts to pause followed by check if the lock is again available.
- If after “N” attempts (controlled by innodb_sync_spin_loops) lock is not available then yield (releasing the cpu control) and enter wait by registering thread in InnoDB home-grown sync array implementation. Also, set a waiter flag after reserving the slot (this ensures we will get a slot in sync-array). Waiter flag is another atomic that is used to coordinate the signal mechanism.
- try_lock (try to get the lock if procured return immediately).
- Exit (unlock mutex)
- Toggling the atomic variable (m_lock_word) to signify leaving the critical section.
- Check if the waiter flag is set. If yes then signal the waiting thread through the sync-array framework.
Looks pretty straightforward and simple. Isn’t it?
Things get complicated with introduction of memory barriers as ignoring them would mean re-ordering can cause race in your code.
- From the above sequence it is pretty clear that while locking m_lock_word (false->true) it could potentially begin the critical section (if CAX succeeds) and so flow shouldn’t execute any statement from the critical section before the lock word is acquired (set to true).
- Going back to our acquire-release barrier section it suggests m_lock_word should take an acquire barrier incase of success (instead of default (seq_cst) as it currently does).
- But wait, there are 2 potential outcomes. What about failure? Even in case of failure, followup actions like spin, sleep and set-waiter should be done only post CAX evaluation. This again suggests use of an acquire barrier for failure case too. (instead of default (seq_cst) as it currently does).
- Now let’s look at the release barrier for m_lock_word. Naturally a release barrier will be placed once a critical section is done when the m_lock_word is toggled.
- There is another atomic variable (waiter flag) that needs to get a proper barrier too.
- Action to set a waiter flag should be done only when flow has ensured it can get a sync array slot. This naturally invites the need for a release barrier so the code is not re-ordered beyond set_waiter. Note: This is different atomic though so the co-ordination of m_lock_word acquire and release will not apply here.
- Same way signal logic should be done only after the waiter flag is cleared so it should use an acquire barrier that will ensure it is not re-scheduled before the clear-waiter. (instead of release as it currently does).
- This will also help us change the waiter-load flag check to use relaxed barrier (vs acquire). (There is a potential catch here; we will discuss it below).
- With all that in place we should able to get rid of explicit memory_fence too.
Anomalies:
- release-barrier on
1 | lock_word |
followed by an acquire-barrier on
1 | waiter |
this could be reordered.
- This was even my understanding of potential risk and I presume that’s why MySQL introduced a fence between these 2 operations. As per the said blog, C++ standard should limit compilers from doing so.
- By using a
relaxed barrier
for the waiter (while checking for its value) there is potential re-ordering that could move load instruction before the m_lock_word release (note: release barrier can allow followup instructions to get scheduled before it).
- If “waiter” is true then a signal loop will be called.
- If “waiter” is false then the signal loop will not be called by this thread but some other thread may call it.
- What if there are only 2 threads and thread-1 evaluates waiter=false by re-ordering it before the release barrier and then immediately posts that waiter is set to true by thread-2 and goes to wait. Now thread-1 will never signal thread-2.
So using a relaxed barrier is not possible so let’s switch it to use an acquire barrier that should avoid moving the followup statement beyond the said point and as clarified above release-acquire needs to follow C++ standard.
All this to help save an extra memory fence. memory-fence intention is to help co-ordinate non-atomic synchronization since our flow has inherent atomic (waiter) using proper memory barrier can help achieve the needed effect.
So with all that taken-care this is how things would look
What we gained from this revamp?
So we achieved 3 things
- Corrected use of memory barrier that helps also clarify the code/flow/developer intention. (This is one of the important thing stressed with use of memory barrier. Correct use will help make the code flow naturally obvious to understand and follow).
- Moved from strict sequential ordering to one-way barrier without loosing on correctness. (acquire and release)
- Avoided use of fence memory barrier meant for synchronization of non-atomic.
Revamp is not justified unless it has performance impact and this revamp is no exception. Revamp helps improve performance on ARM in range of 4-15% and on x86_64 in range of 4-6%.
Conclusion
Atomics are good but memory-barrier make them challanging and ensuring proper use of these barriers is key to the optimal performance on all platforms. Adaptation of barrier is catching up but still naive (though present in C+11) as most of the softwares recently started adapting to it. Proper use of barrier help clear the intention too.
If you have more questions/queries do let me know. Will try to answer them.