译者: bzhaoopenstack
作者: Krunal Bauskar
原文链接: https://mysqlonarm.github.io/ARM-LSE-and-MySQL/
来看Mysql大牛Krunal带你分析LSE在Mysql上的情况。
ARM’s LSE (for atomics) and MySQL
ARM 在其 ARMv8.1规范中引入了 LSE (Large System Extensions)。这意味着如果你的处理器是兼容 ARMv8.1的,它将支持 LSE。LSE 的目的是优化原子指令,通过使用单个 CAS (比较并交换)或 SWP (用于交换)等替换旧式的独占负载存储… … 众所周知,上述扩展本质上会提高使用原子的应用程序的性能。
理解LSE
为了更好地理解 LSE,让我们看一个工作示例,看看代码是如何生成的,以及可能的优化。
LSE turned off


正如您所看到的,有一个用于执行 CAS 的循环。加载值,检查期望值,如果不同,然后存储值。主循环是一个5步进程与2个独占指令与各自的内存顺序。SWAP 也有一个检查存储是否成功的循环。
ARM 有多种不同的加载/存储指令,因此在继续之前,让我们花一分钟理解这些变体。

stlxrb: 与发布语义/排序互斥的存储。提供对上述cacheline的独占访问权。“b”表示字节。(其他 half-word (2), word(4), double-word (8))。
stlrb: 与发布语义/排序互斥的存储。帮助建议只进行语义排序,而不进行独占访问。
strb: 非原子变量的普通存储(没有排序语义)
自然有人会问,为什么 seq-cst 和 release memory order 都会产生相同的asm指令。这是因为 ARM-v8中的store-release in ARM-v8 is multi-copy atomic,也就是说,如果一个agent看到了存储-释放,那么所有agent 都看到了存储-释放。没有要求普通存储为多拷贝原子存储。[类似于 x86_64中的 mov+fence 或 xchg ]。
LSE 开启
所以现在让我们看看如果我们现在打开 lse 会发生什么。LSE 支持是在 ARM-v8.1规范中添加的,因此如果默认编译已经完成,gcc 将尝试使二进制文件与更广泛的 aarch64处理器兼容,并且可能无法启用特定的功能。为了支持 lse 用户需要指定额外的编译标志:
有多种方式打开lse:
- 使用 gcc-6+ 编译,指定 lse 标志为-march = armv8-a+lse
- 通过指定 ARMv8.1(或更高版本)使用 gcc-6+ 编译(这将自动启用所有 ARMv8.1功能)。-march = ARMv8.1-a

不再有 while 循环。单条指令(CASALB)执行比较和交换(负责加载和存储) ,与 SWAPLB 执行交换的方法相同。看起来是进行了优化。更多关于性能的信息请见下文。
但是有一个问题,如果二进制文件是用 +lse 支持编译的,但是目标计算机不支持 lse,因为它只与 arm-v8兼容。通过引入 -moutline-atomics ,gcc-9.4+ 解决了这个问题(使用-mno-outline-atomics禁用 gcc-10.1启用的默认值)。GCC 自动匹配带有动态检查变量(lse 和 non-lse)的代码。运行时作出决定,并执行相应的变量。
让我们看看如果使用 gcc-10(使用 -moutline-atomic使其在所有 aarch64机器上兼容)编译会发生什么)
| code | asm (perf output) |
|---|---|
| bool expected = true; flag.compare_exchange_strong(expected, false); | <aarch64_cas1_acq_rel>: __aarch64_cas1_acq_rel(): │ adrp x16, 11000 <data_start> │ ldrb w16, [x16, #25] │ ↓ cbz w16, 14 │ casalb w0, w1, [x2] │ ← ret │14: uxtb w16, w0 │ 18: ldaxrb w0, [x2] │ cmp w0, w16 │ ↓ b.ne 2c │ stlxrb w17, w1, [x2] │ ↑ cbnz w17, 18 │2c: ← ret |
请注意用于选择适当逻辑的分支指令(用绿色突出显示)。
LSE 的表现
虽然这些听起来很有趣,但是真的有帮助吗?如果新的指令需要更多的周期怎么办。只有一种方法可以找到答案: 基准测试。
基准测试: 每个线程(总共 n 个线程)都尝试获得锁,这会导致严重的争用。一旦线程拥有了互斥锁,它就会执行基于 crc32的软件,在释放它之前让 cpu 一直处于繁忙状态。每个线程都执行这个流程 m 次。
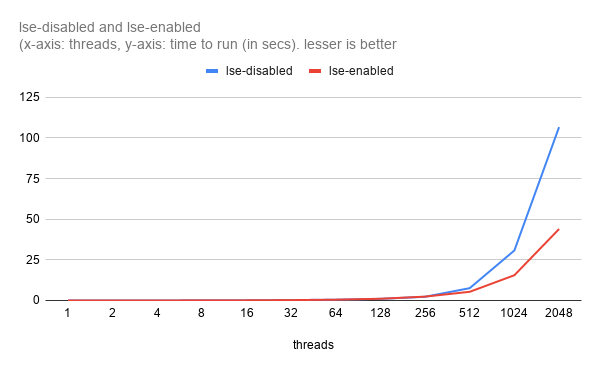
Machine: Bare-Metal with 128 cores ARM Kunpeng 920 2.6 Ghz.
- 用例表示一个严重的争用,每个线程主要花费时间获得锁。这样的工作负载非常快(crc32在16KB 块上)
- 这清楚地证明,LSE严重争用的条件下起到帮助作用。
但是微基准测试由于应用本身的特性,包括其他重叠部分,如 IO、其他处理元素等,有时不能显示原始应用所需的增益。.现在让我们评估一下lse使能在 MySQL 性能。
MySQL benchmarking with LSE
环境描述:
- Server: MySQL-8.0.21, OS: CentOS-7
- Sysbench based point-select, read-only, read-write, update-index and update-non-index workload.
- Executed for higher scalability (>= 64) to explore contention.
- Configuration: 32 cores (single NUMA) ARM Kunpeng 920 2.6 Ghz (28 cores for server, 4 for sysbench)
- Tried 2 use-cases uniform, zipfian (more contention)
- baseline=lse-disabled, lse=lse-enabled (-march=armv8-a+lse).
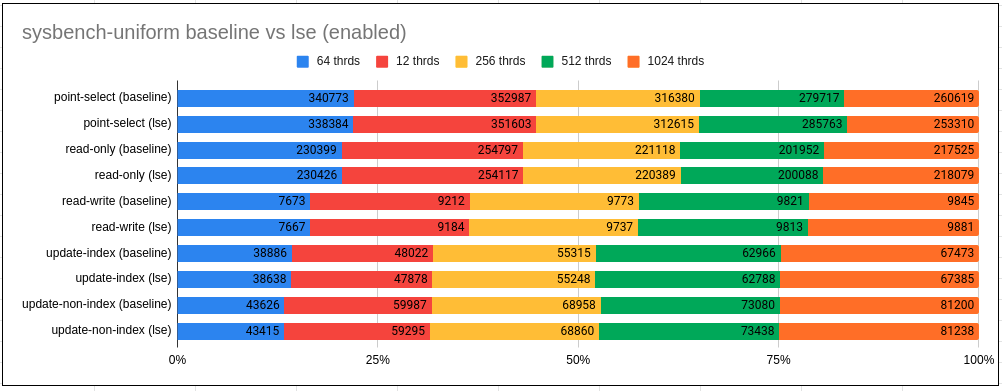
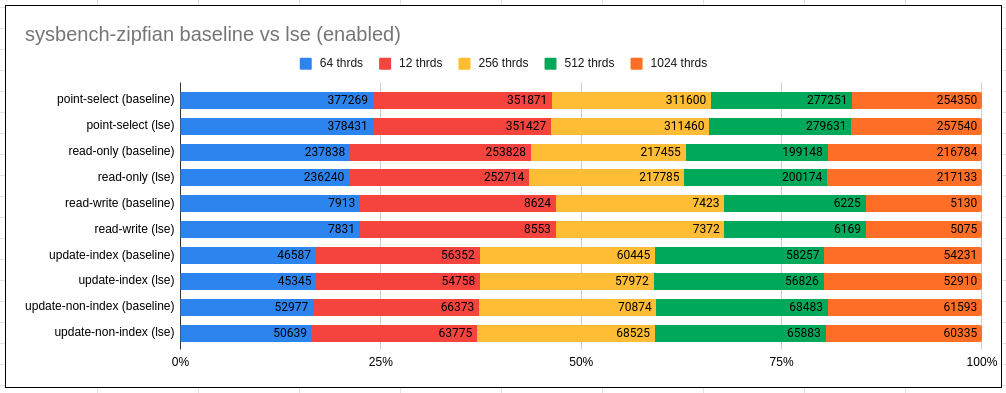
观察结果:
- 在Uniform cases ,使用LSE下,我们几乎看不到任何区别
- 在Zipfian cases, LSE对于更新用例,会略微退化,但是始终如一(2-4%).
总结
LSE 作为特性看起来很有前途,但在 MySQL 用例中确实没有多少提升。可能一旦 MySQL 被调整到使用更多的原子,LSE 可能会显示 +ve 的差异。在那之前,如果不启用 LSE,我们在Mysql不会失去任何性能。
如果有疑问,请联系我,或在下方留言
ARM introduced LSE (Large System Extensions) as part of its ARMv8.1 specs. This means if your processor is ARMv8.1 compatible it would support LSE. LSE are meant to optimize atomic instructions by replacing the old styled exclusive load-store using a single CAS (compare-and-swap) or SWP (for exchange), etc…. Said extensions are known to inherently increase performance of applications using atomics.
Understanding LSE
To better understand LSE let’s take a working example to see how the code is generated and possible optimization.
LSE turned off
As you can see there is a loop for doing CAS. Load the value, check with expected value and if different then store the value. Main loop is a 5 step process with 2 exclusive instructions with respective memory ordering. SWAP too has a loop for checking if the store is successful.
ARM has multiple variant of load/store instructions so before we proceed let’s take a minute to understand these variants.
stlxrb: store exclusive with release semantics/ordering. Provide exclusive access to the said cache line. “b” represents byte. (other variant half-word (2), word(4), double-word (8)).
stlrb: store with release semantics/ordering helping suggest ordering semantics only but not exclusive access.
strb: normal store to a non-atomic variable (no ordering semantics)
Naturally one may ask how come both seq-cst and release memory order generate the same asm instruction. This is because store-release in ARM-v8 is multi-copy atomic, that is, if one agent has seen a store-release, then all agents have seen the store-release. There are no requirements for ordinary stores to be multi-copy atomic. [Something similar to mov+fence or xchg in x86_64 domain].
LSE turned on
So let’s now see what would happen if we now turn-lse on. LSE support was added with ARM-v8.1 specs and so if the default compilation is done, gcc will try to make binary compatible with a wider aarch64 processors and may not enable the specific functionality. In order to enable lse user need to specify extra compilation flags:
There are multiple ways to turn-on lse:
- Compile with gcc-6+ by specifying lse flag as -march=armv8-a+lse
- Compile with gcc-6+ by specifying ARMv8.1 (or higher) (that will auto-enable all ARMv8.1 functionalities). -march=armv8.1-a
No more while loop. Single instruction (CASALB) to do the compare and swap (that takes care of load and store) and same way SWAPLB to do the exchange. Sounds optimized. More about performance below.
But there is one problem, what if binaries are compiled with +lse support but the target machine doesn’t support lse as it is only arm-v8 compatible. This problem is solved with gcc-9.4+ by introducing -moutline-atomics (default enabled with gcc-10.1 can be disabled with -mno-outline-atomics). GCC auto emits a code with dynamic check with both variants (lse and non-lse). Runtime a decision is taken and accordingly said variant is executed.
Let’s see what is emitted if compiled with gcc-10 (with -moutline-atomic making it compatible on all aarch64 machines)
| code | asm (perf output) |
|---|---|
| bool expected = true; flag.compare_exchange_strong(expected, false); | <aarch64_cas1_acq_rel>: __aarch64_cas1_acq_rel(): │ adrp x16, 11000 <data_start> │ ldrb w16, [x16, #25] │ ↓ cbz w16, 14 │ casalb w0, w1, [x2] │ ← ret │14: uxtb w16, w0 │ 18: ldaxrb w0, [x2] │ cmp w0, w16 │ ↓ b.ne 2c │ stlxrb w17, w1, [x2] │ ↑ cbnz w17, 18 │2c: ← ret |
Notice the branching instruction (highlighted in green) to select appropriate logic.
LSE in action
While all this sounds interesting but does it really help? What if the new instruction takes more cycles. Only one way to find out: Benchmark.
Benchmark: Simple spin-mutex with each thread (total N threads) trying to get the lock there-by causing heavy contention. Once the thread has the mutex it performs software based crc32 keeping the cpu bit busy before releasing it. Each thread does this M times.
Machine: Bare-Metal with 128 cores ARM Kunpeng 920 2.6 Ghz.
- Use-case represent a serious contention with each thread mostly spending time for obtaining lock. Workload as such is pretty quick (crc32 on 16KB block).
- This clearly proves that LSE helps in heavily contented cases.
But micro-benchmark sometime fails to show the needed gain with original application due to nature of application including other overlap components like IO, other processing element, etc… So let’s now evaluate MySQL performance with lse-enabled.
MySQL benchmarking with LSE
Workload:
- Server: MySQL-8.0.21, OS: CentOS-7
- Sysbench based point-select, read-only, read-write, update-index and update-non-index workload.
- Executed for higher scalability (>= 64) to explore contention.
- Configuration: 32 cores (single NUMA) ARM Kunpeng 920 2.6 Ghz (28 cores for server, 4 for sysbench)
- Tried 2 use-cases uniform, zipfian (more contention)
- baseline=lse-disabled, lse=lse-enabled (-march=armv8-a+lse).
Observations:
- With Uniform we hardly see any difference with use of LSE
- With Zipfian LSE tend to regress marginally but consistently (by 2-4%) for update use-cases.
Conclusion
LSE as feature looks promising but fails to perform in MySQL use-case. May be once MySQL is tuned to use more atomics, LSE could show a +ve difference. Till then nothing we would not loose if LSE is not enabled.
If you have more questions/queries do let me know. Will try to answer them.